Completing the modern data stack with a series A from Sequoia | Census
Boris JabesFebruary 18, 2021
Boris is the CEO of Census. Previously, he was the CEO of Meldium, acquired by LogMeIn. He is an advisor and alumnus of Y Combinator. He enjoys nerding out about data and technology, 8-bit graphics, and helping other startup founders.
I’m thrilled to announce that Census has raised a $16 million Series A, led by Sequoia Capital. Andreessen Horowitz (who led our seed) is also participating, along with operators like Dylan Field (Figma CEO), Jason Warner (GitHub CTO), Akshay Kothari (Notion COO), Parker Conrad (Rippling CEO), Josh Ferguson (Mode Chief Architect), Bryant Chou (Webflow CTO), Joe Thomas (Loom CEO), Patrick McKenzie (Stripe) and Guillaume Cabane. This round brings our total amount raised to just over $20 million.
We're also launching the Census Startup Program to empower startups to easily build the last mile of the modern data stack. Companies with fewer than 40 employees and less than $10MM in funding will be able to use Census for a flat rate of $100 per month.
In 2018, we started with a simple product that helped business teams sync data from their cloud warehouses into their favorite tools. Since then, the data landscape has changed a lot – now we're starting to see analytics & data move to the core of all company operations. We launched publicly last year with the world's first reverse ETL that natively publishes from any data warehouse (we dubbed this the "missing piece" in the modern data stack). The reaction has been nothing short of phenomenal – Census is now syncing analytics for over half a billion users every day.
We're lucky to support some pretty amazing teams using Census, like Canva, Figma, Drizly, Heap Analytics, Netlify, Mode Analytics, Notion, and Chorus.ai just to name a few. These organizations are unified by a shared focus on delivering personalized experiences for every customer, even when they've scaled to hundreds of millions of users.
To do this, they treat data as a central pillar of their organization, instead of just paying lip service to being "data-driven." Putting data teams on the critical path of every business operation has emerged as the category of Operational Analytics – and has been the driving force for our company.
Operational Analytics, aka. the Data Warehouse as Hub
Three years ago, we asked, “Why are we relying on a clumsy tangle of wires connecting every app when everything we need is already in the warehouse? What if you could leverage your data team to drive operations?”
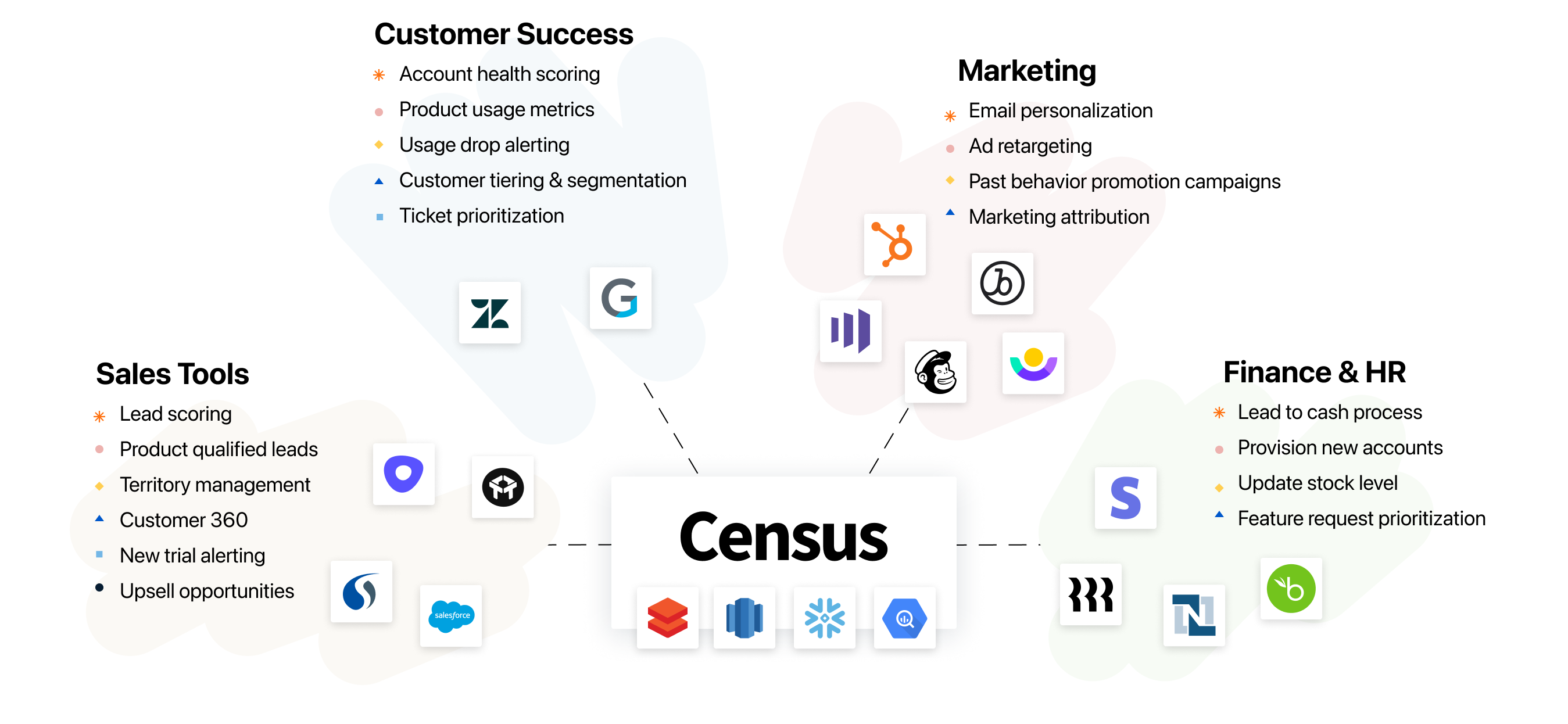
When the data warehouse is connected to the rest of the business, the possibilities are limitless. When we launched, our focus was enabling product-led companies like Figma, Canva, and Notion to drive better marketing, sales, and customer success. Along the way, our customers have pulled Census into more and more scenarios, like auto-prioritizing support tickets in Zendesk, automating invoices in Netsuite, or even integrating with HR systems. With our growing library of native integrations, Census makes it possible for data models in your cloud data warehouse to power any business workflow.
The performance improvements we've seen in the modern data stack (fast incremental ingestion from our partners at Fivetran, separated workloads on Redshift, improving latency from Snowflake, the arrival of Delta Lake, etc.) finally make it possible for the data warehouse to act as a new kind of CDP (Customer Data Platform). One that enables hyper-scale businesses to deliver the attention and personalization that customers historically only get from, say, a small neighborhood boutique. This is the promise of Operational Analytics.
The Rise of the Data Ops Ecosystem
Census is part of a larger movement in the data ecosystem, one in which the precepts of Engineering and DevOps are washing over the world of analytics. Marc Andreessen famously said "software is eating the world." Our team has always believed in the corollary: "software practices will eat the business." We've made it our mission from day one to help data teams build solutions like engineers. And we’ve worked with amazing partners in bringing this vision to reality.
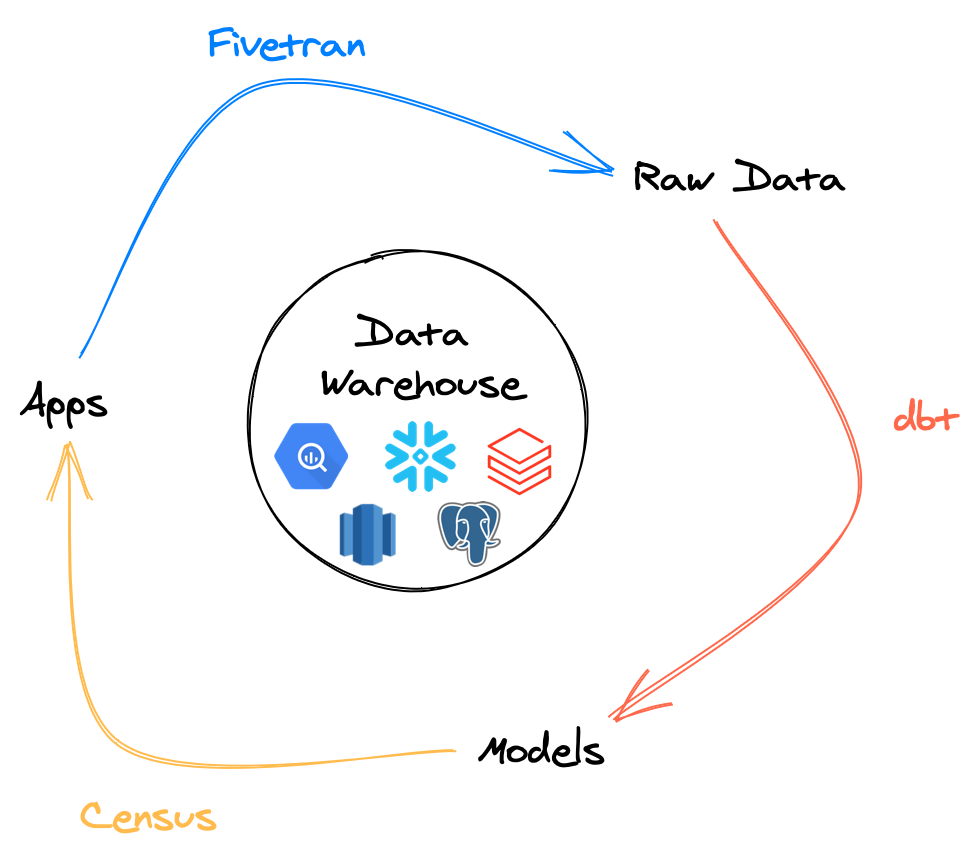
Fivetran + dbt + Census = Feedback Loop
Census takes models and insights from a data warehouse then validates and deploys the results so they can be put to work in other teams (ie. the real world). With our native understanding of dbt model versions, you can safely orchestrate your entire data operations from input to output. Census closes the feedback loop to make the whole much greater than the sum of the parts.
But what most drives this movement—and what we love most about it—is the amazing community of developers, analysts, and operations experts that all help each other to build better systems. Our partners at Fishtown have fostered one of the most inclusive and helpful communities, which supported and embraced Census early on – led by the intrepid Claire Caroll (fun fact: she helped popularize our “reverse ETL” concept in 2019). We participate in our small way with tool talks and office hours. There’s real excitement around the modern data stack, which is why we created our new startup program so folks could adopt this stack regardless of company size or budget.
The Future: Data as a Product
The next decade is going to be an exciting one for data teams, and our early customers are pointing the way. Instead of constantly building (and fixing) one-off reports, data teams are poised to become a central nervous system for the business.
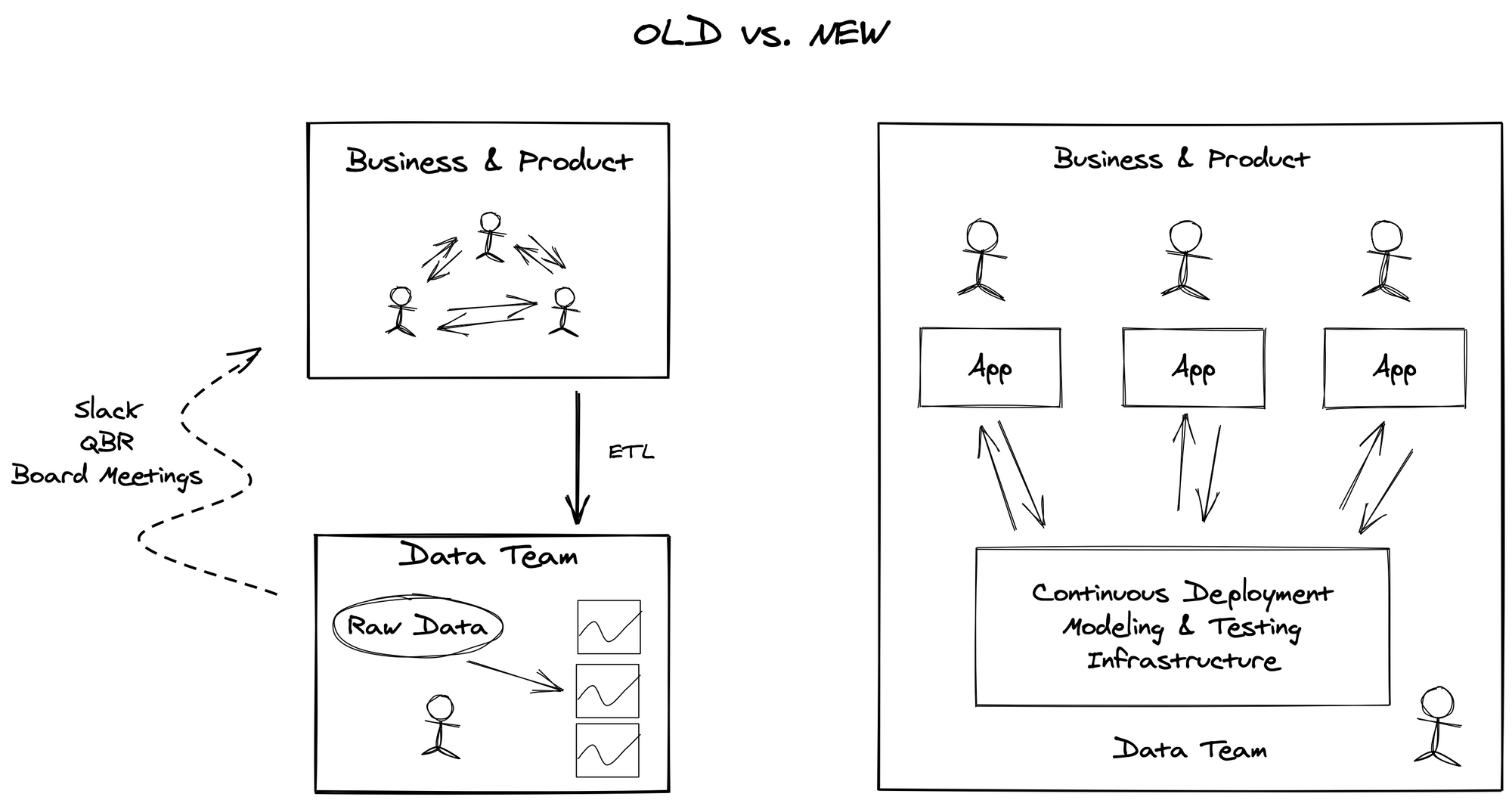
Traditionally, BI teams have been focused on asynchronous, batch processing instead of real-time, personalized processing. Analysts build reports to answer questions about what happened in the business, which is like looking at the rear view mirror. This data architecture could crunch raw data into KPIs and charts but wasn’t optimized for understanding individual users or entities. Even worse, it was disconnected from day-to-day operations, which forced data teams to do painful periodic reconciliations with the business.
Operational Analytics changes the role of data teams
Modern data teams are built differently. Instead of a data sink, they are a platform for applications, analysis, visualization – and most importantly, action. Instead of focusing on data aggregation for BI visualization, a new modeling layer must emerge that captures clean, unified yet individualized entities that can be used in any application. In order to support all these scenarios, a few things are crucial.
The data infrastructure must be scalable, efficient, and real-time.
The data modeling layer must be versioned, tested, deployed, and ultimately standardized for broad consumption.
The data pipelines must reach any application, and be seamlessly monitored to create tight feedback loops with every part of the organization
The Road(map) Ahead
There’s a ton of capabilities in Census and even more to come. Here’s some of the areas we’ve been working on and plan to expand upon this year.
Code-Based Orchestration. Today, we sync models seamlessly from a warehouse but we want to push the bar forward here and make every Census workflow versionable and pluggable into larger orchestration systems.
Deeper Data Validation. When your data models are connected to business systems, failures become much worse (which is a good thing, after all if your mistakes have no impact, what’s the point?). Census is your last line of defense before the data is live so validating your data is key.
Visual Query Experience. When data becomes a product, it means you have more consumers. Many of these consumers need a way to interact with models with a simple UX, which furthers our goal of data reaching every part of the organization.
If this sounds like a lot, it's because it is. We're embarking on a long journey to transform data organizations into product teams. Teams that can scale to support many users and many use cases. By shifting into this central role, data teams stop being backwards-looking and become the biggest drivers of change in an organization – the ultimate feedback loop.
Join us
The companies & leaders who understand this will certainly succeed and I look forward to seeing an amazing cohort of Chief Data Officers in the decade to come. There is a huge amount of work ahead of us and I am unbelievably excited to tackle these problems every day. Empowering people with tools has been my passion ever since I started my career in technology. If you want to help make an impact and move the needle on the entire data ecosystem, come join our team. We’re small but mighty and hiring for every position. You can reach me on Twitter or via email.