How Data Orchestration Unleashes the Full Power of Your Data
Allie BeazellMay 27, 2021
Allie Beazell is director of developer marketing @ Census. She loves getting to connect with data practitioners about their day-to-day work, helping technical folks communicate their expertise through writing, and bringing people together to learn from each other. Los Angeles Metropolitan Area, California, United States
The universe of data within modern companies is ever-expanding. It’s exciting, there’s more data than ever to dig into, but with more data comes more governance, sync schedules, and processing problems.
Companies need to break silos between data sources and storage to truly operationalize all the information they’re collecting. However, just adding new tools to the mix won’t solve the problem (it can actually make it much, much worse). To break down silos between their data sources and overcome system sprawl, they need better data governance combined with data orchestration.
Data orchestration makes it possible for organizations to automate and streamline their data, operationalizing it so that this valuable information can be leveraged to drive real-time business decisions. By some estimates, 80% of the work involved in data analysis comes down to ingesting and preparing the data, which means data orchestration can cut down on loads of your data processing and scheduling time.
As you know, we here at Census are big fans of anything that breaks down silos and improves data quality and data access. ❤️ That’s why we’re excited to dive into the top of data orchestration, what it is, why you should care, and some of the tools you can use to get started with orchestration today.
What is data orchestration?
Data orchestration can look a little different at each stage of your data pipeline, so for this article, we’re focusing on a general, 20,000-foot definition that captures it from end to end:
Data orchestration is the leveraging of software to break down data silos between sources and storage locations to improve data accessibility across the modern data stack via automation. It improves data collection, data preparation and transformation, data unification, and delivery and activation.
When a company invests in the software necessary to support data orchestration at each layer of their stack, they’re better able to connect their systems and ensure they have access to all their information in relative real-time.
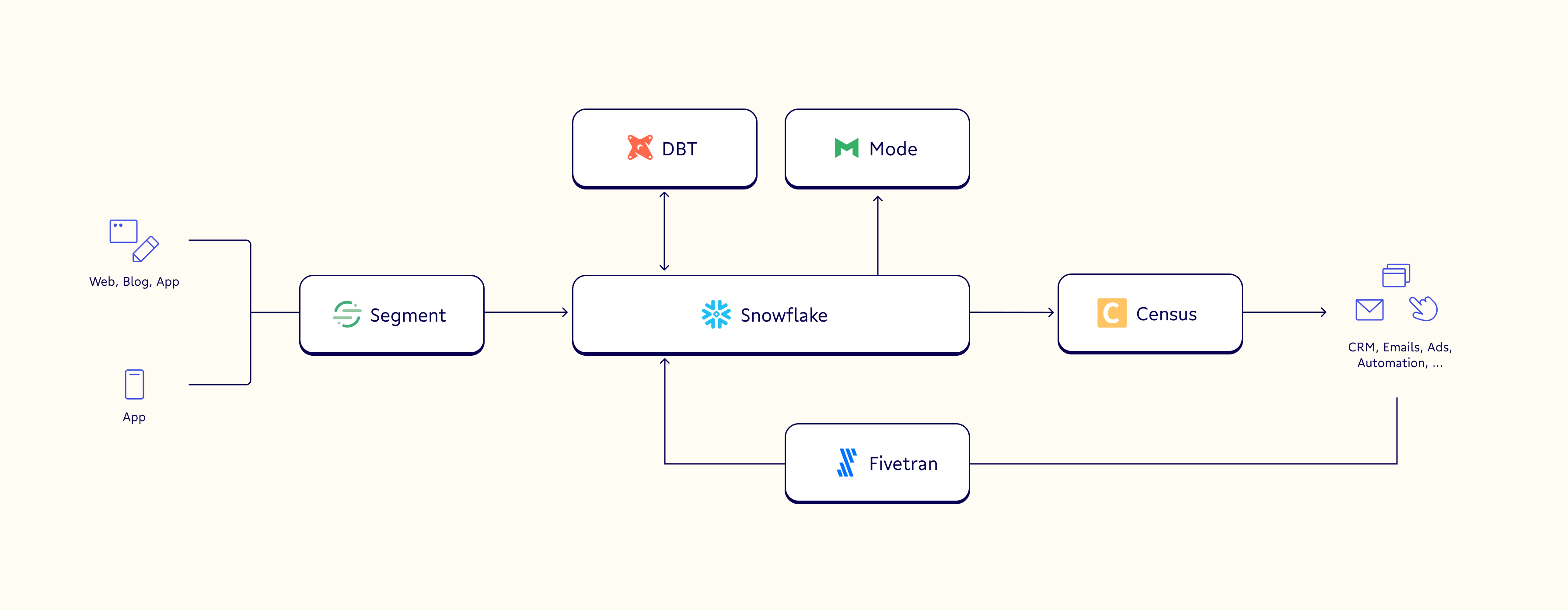
Data orchestration services automate the movement of data between your event tracking, data loader, modeling, and data integration tools (as seen above within a sample modern data stack of our favorite tools.
As we mentioned in the definition above, there are four main processes that data orchestration helps with across your stack:
Data collection: End-to-end data orchestration services handle data ingestion to collect important data from your customer touchpoints, often via SDKs and APIs that can be directly integrated with your applications.
Data preparation and transformation: Once your data has been collected, orchestration services help to standardize and check properties and values at your collection points. These values--such as names, times, and events--can be mutated to match a standard schema.
Data unification: Data orchestration services can help organizations unify their data into a pool that is more valuable than the individual input streams by themselves. This can be used to create a single, unified view of customers by stitching together data collected from websites, point of sale devices, and applications to help you understand individual user behavior over time.
Delivery and activation: Once unified customer profiles have been created, data orchestration services can send this valuable information to the tools that your team uses every day, including BI platforms, data analytics tools, and customer management solutions.
You can picture your data pipeline like a river, with a handful of tributaries (data sources) feeding into it. Imagine that you’re trying to create a reservoir (data warehouse) near the river’s mouth with a dam that will generate enough electricity (insight/value) to provide power to a nearby town (customers).
Without data orchestration, the folks building your dam and controlling the reservoir level have to manually run upstream and release water gates on each source. It takes hours (and a lot of work). With data orchestration, the crew manning the dam can run operations programmatically to automate the water flow, without the literal leg work. This means they can spend more time monitoring the energy generated and getting it to the town.
Historically, this manual leg work took the form of cron jobs, which data engineers and data scientists wrote in Python. This meant that things like failure handling had to be done on a job-by-job basis. However, as data stacks grew and become more complex to handle larger and larger volumes of data (more water, if we’re sticking with the metaphor), engineers couldn’t keep the manual work up.
This manual work--combined with disparate legacy systems--creates eddies of dark data in the sources leading to your reservoir, preventing valuable information from reaching your team for analytics, customer engagement, or any other activity.
Thankfully, there are frameworks today that support automated data orchestration and pipeline monitoring to prevent data from going dark. That’s why we believe data orchestration is a core part of the modern data stack.
Technically speaking, data orchestration solutions are filed by DAGs (directed acyclic graphics), which are a collection of the tasks that you want to run. These tasks are organized and run based on their dependencies.
Each node of the DAG represents a step of the tasks in the process. It’s generally defined by a Python script, which makes it easy for data scientists to use.
For example, take the four-step extract, load, transform, and sync the process as a DAG. In order for the transform step to happen, data has to be loaded, and in order for data to be loaded, it first has to be extracted. Then, once all that has happened, a reverse ETL tool like Census can take care of the downstream work with trigger sync via API.
More precisely, DAGs within data orchestration flows can help with:
Data organizing, cleansing, and publishing in the warehouse
Business metric computation
Rule enforcement for campaign targets and user engagement through email campaigns
Data infrastructure maintenance
Training machine learning models
While Census's ability to orchestrate the last mile of your pipeline is unique, there are a variety of orchestration services on the market that can help with the rest of the flows above.
How data orchestration tools have evolved
Like all technology, data orchestration tools change often to keep pace with the data management needs of evolving organizations. Each new generation of data orchestration services emphasizes a more and more specific use case.
First-generation data orchestration tools like Airflow are primarily focused on improving usability for data scientists with the introduction of Python support (vs previous tools that required queries to be written in JSON and YAML). This improved UI made it easier for data teams to manage their pipeline flows without getting as caught up in the process.
Second-generation data orchestration tools like Dagster and Prefect are more focused on being data-driven. They’re able to detect the kinds of data within DAGs and improve data awareness by anticipating the actions triggered by each data type.
These data-driven capabilities can be divided into two categories:
Active approaches that pass data between steps and systems.
Passive approaches wait for an event (cue) outside the DAG to occur before triggering a task (particularly useful for continuous model training).
For most use cases, active data orchestration approaches will work well. However, as stacks and data flow to become more complex, passive approaches can be leveraged to orchestrate these stacks.
What’s the difference between orchestrated and un-orchestrated data?
The difference between orchestrated and unorchestrated data stacks is the difference between operationalizing your data to fuel future decisions vs reacting to and wrestling with your past data to troubleshoot.
This is because legacy systems and stacks that are still in the process of being migrated to the cloud tend to create more data silos than they break down. It takes deliberate governance and design decisions to revamp these legacy stacks to overcome technical debt and leverage data orchestration tools in your data ecosystem.
Why should you care about data orchestration?
Data orchestration breaks down the silos that separate your data stack and make your data stale as it sits in dark data eddies. Many companies may set their engineers on the warpath to building DIY orchestration solutions, but those will quickly become irrelevant as the stack changes (plus, it requires a lot of expensive rework and annoys your engineers). Beyond saving data engineering time, orchestration also helps you:
Improve data governance and visibility
Leverage fresher customer data
Ensure data privacy compliance
Orchestration prevents the growing pains many companies experience by giving them a scalable way to keep their stacks connected while data flows smoothly. It’s great for companies that:
Have a lot of data systems that need to be pulled together.
Have started to integrate the modern data stack and want to get more use out of it.
Have just started building their first stack and want to establish a strong foundation to handle future scale.
Data orchestration ensures that you and your team have the freshest data possible, without your engineers having to manually run jobs overnight to serve it to you. These services let you automate your sync schedule and use trigger APIs to update downstream dependencies.
Improved workflows for engineers and analysts
Using manual cron jobs and Python scripts is a slow method for getting you the data you need. In today’s data world, the speed and volume of data collection have grown so much that data teams and engineers can’t possibly keep up with the manual organization of it.
Rather than relying on one overloaded engineer to help fetch the data you need from multiple warehouses and storage systems, you can use data orchestration platforms to automatically transform and deliver it to you.
This reduces the time engineers and data scientists have to spend on data collection and transformation and empowers data teams to make better decisions in real-time.
Improved data governance and visibility
Siloed and disparate data sources are hard to govern and get visibility into. To use orchestration tools effectively, companies must audit and organize their stack, creating more visibility in the process. This makes it easier for you to govern your data and improves the overall confidence in and quality of it.
At its heart, data orchestration is about making your data and systems more useful for the systems and people that consume them.
Leverage fresher customer data
RevOps folks know that the key to unlocking better insights into customers lies in data. The automation of your data processes from end to end makes it easier than ever for data consumers to operationalize their data use.
With data orchestration functionality integrated with your pipeline, the data from campaigns, webcasts, web apps, and other customer data sources can be easily collected, transformed, loaded into your warehouse, and then sent back out to platforms like Salesforce and Marketo via reverse ETL tools.
This information availability helps your RevOps teams score leads and accounts, create a single view of each customer, establish audience associations, and more.
Ensure data privacy compliance
With great data comes great responsibility. GDPR, CCPA, and other data privacy laws require organizations to be good stewards of their customer data by providing documentation that shows it was collected correctly and ethically.
If you’re working within a chaotic, disparate stack, this kind of paper trail is hard to maintain and show. However, with a modern data stack outfitted with data orchestration, you can easily get a detailed view of the when, where, and why of each data point you’ve collected.
This also makes it easier for organizations to delete information on request, something that’s difficult to fully do if part of the data in question has been held indefinitely upstream due to poor data flow.
Improve your data orchestration, improve your operations
Cool, so you’ve learned all this fancy information about data orchestration. But now what? Well, if you’re still wrestling with your legacy stack and looking to make the move to the modern data stack, check out this resource on upgrading to the modern data stack.
If you’re ready to orchestrate your modern data stack (or if you’re just looking for orchestration for the last mile of your pipeline from your warehouse to destinations like Salesforce), we have great news: Census has released trigger syncs via API and dbt Cloud (with more integrations coming soon). 🎉