Customer Stories
Built With Census Embedded: Labelbox Becomes Data Warehouse-Native
TABLE OF CONTENTS
Tutorials

Data enrichment is a powerful technique for adding valuable context to your customer data, and it’s simple in theory – given a bit of data about a record (e.g. a user's email or the IP of a web session), tell me more information about it so I can take effective action (e.g. map the email domain to a company or map the IP to a geolocation). In practice, however, it can be difficult to integrate a data enrichment process into an existing ELT pipeline, for a few reasons:
- Maintaining Freshness: How recent are the results being correlated with my data? This may be a function of how often external datasets are loaded or how up-to-date your third-party data provider’s information is.
- Ensuring Consistency: Once data is enriched with new attributes, can I easily push those attributes to my warehouse and SaaS tools to maintain a synchronized data model?
- Limiting Resource Usage: Enrichment processes can be expensive in storage costs (to maintain huge third-party datasets), processing time, and API quota usage for paid enrichment services. And enrichment processes shouldn’t unnecessarily repeat the same work over and over again.
In this post, I’ll share our recipe for enriching our own customer data at Census using the Clearbit API, Snowflake External Functions, and dbt to enrich data correctly and efficiently over large datasets.
One note before we begin, if you’re new to data enrichment: there’s a key difference between enriching using a dataset and enriching using an API. Some enrichment pipelines make use of third party datasets that can be purchased in their entirety – you can see many examples of these in the Snowflake Data Marketplace. This kind of data can be easier to work with because you can rely on your warehouse to efficiently LEFT JOIN to these datasets and materialize the result on a schedule. However, an enrichment API doesn’t give you the full dataset to work with; it replies to your queries (one at a time or in bulk) in a request-reply style to tell you if the API has additional data for the company or person in question. These are more challenging to work with in a data warehousing context, and we built this pipeline so that we can perform both types of enrichment without leaving the comfort of our warehouse SQL environment.
Snowflake's External Functions
External functions are a recent addition in modern data warehouses. An external function is like a traditional user-defined function (UDF), but it allows you to break free of the database sandbox by calling an external handler to calculate results. For example, Redshift has basic support for external functions that call Lambda functions to compute their results.
Snowflake's external functions call out to an AWS API Gateway endpoint to retrieve results, which allows us to connect many different handlers, including Lambda functions. Calls from SQL will be batched into JSON HTTP requests and proxied to the configured handler, which needs to unwrap the batch items, calculate appropriate values, and then return a batch of results as JSON. Setting up a gateway and handlers in AWS for the first time isn’t trivial, but the design allows a lot of flexibility. I won't go through that process in this post but you can read about it in Snowflake's documentation. We automate this using a Terraform module, which we hope to open source soon. Feel free to contact us if you’re curious!
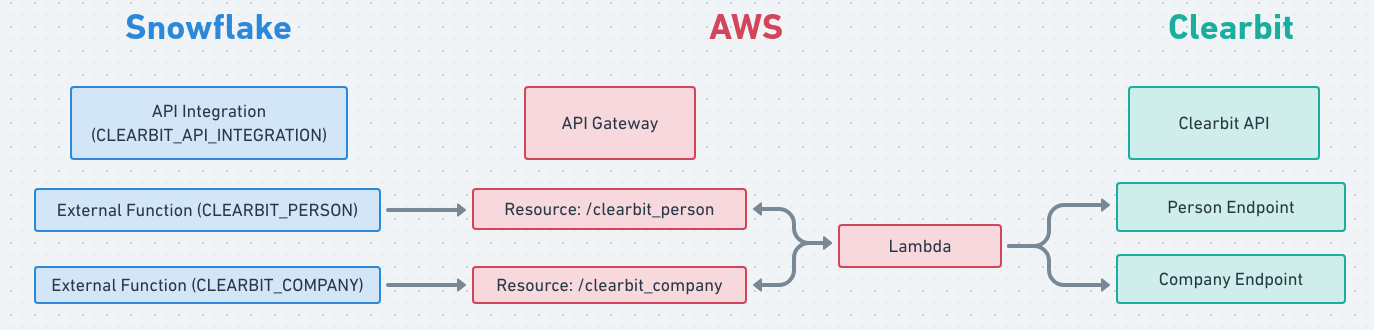
Once the remote gateway is set up, we need to set up an API integration in Snowflake and create one or more external functions that use the integration:
CREATE OR REPLACE API INTEGRATION clearbit_api_integration
api_provider=aws_api_gateway
-- This role is created during gateway setup and is the role that a Snowflake-managed user will assume
api_aws_role_arn='arn:aws:iam::123456789012:role/gateway_access_role'
api_allowed_prefixes=('https://<gateway-id>.execute-api.us-west-2.amazonaws.com/production')
enabled=true;
CREATE OR REPLACE EXTERNAL FUNCTION clearbit_person(email_col VARCHAR)
RETURNS VARIANT
API_INTEGRATION = clearbit_api_integration
AS 'https://<gateway-id>.execute-api.us-west-2.amazonaws.com/production/clearbit_person';
CREATE OR REPLACE EXTERNAL FUNCTION clearbit_company(domain_col VARCHAR)
RETURNS VARIANT
API_INTEGRATION = clearbit_api_integration
AS 'https://<gateway-id>.execute-api.us-west-2.amazonaws.com/production/clearbit_company';Once the API Integration and external functions are created, assuming that the backing gateway is configured properly and our Lambda that forwards requests to Clearbit's API is implemented properly, we should be able to call them like any other SQL function:
Caching for Performance (and saving your API quotas)
Although our CLEARBIT_PERSON function now works properly, we have another issue to contend with: every time our ELT pipeline steps run, we will call Clearbit's API through the external function handler, eating into our API quota and running slowly due to the overhead of retrieving remote data. Since we don't expect the enrichment data to change with high frequency and can probably tolerate some level of staleness, we can save API invocations and execution time by caching the lookup results.
Let's start with a simple example with a users model that we'd like to enrich with each user's title, company name, and company domain. We'll accomplish this with a handful of dbt models that combine to form these logical data flows:
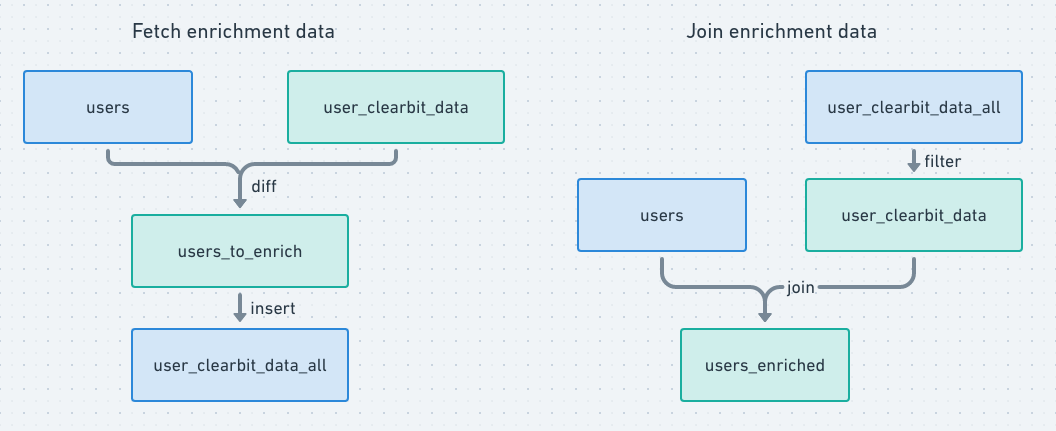
Notice that there is some overlap between the model nodes, as these flows form the following topology when combined.
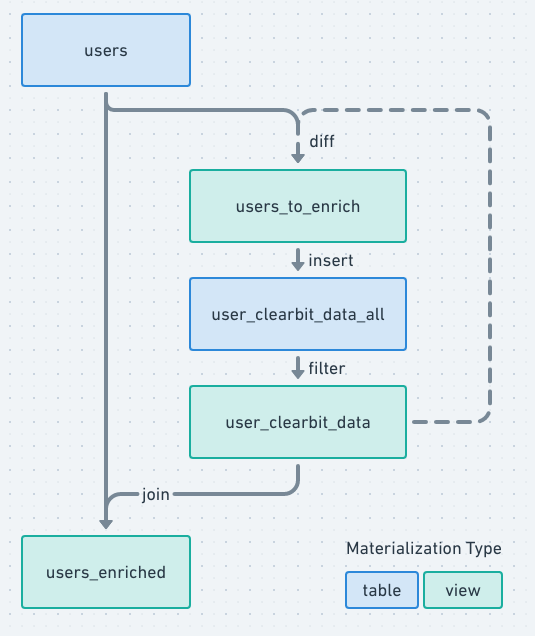
The pieces that we'll want in place are:
users – The primary user data table
user_clearbit_data_all – A table to hold Clearbit data for each email we look up, along with a timestamp when it was fetched. This may have multiple records per email when data is stale and needs to be refetched.
Since we're using dbt to express our models, this ends up as part of the definition of model user_clearbit_data_all, which uses an incremental materialization strategy (meaning that query results are added to the existing data in the table rather than overwriting them).
-- new rows to insert into user_clearbit_data_all
SELECT
CURRENT_TIMESTAMP AS fetched_at,
email,
CLEARBIT_PERSON(email) AS clearbit_data
FROM user_clearbit_data – A view to filter user_clearbit_data_all to the freshest version fetched and exclude any stale data
WITH
fresh_fetches AS (
SELECT *
FROM
-- impose definition of stale -> fetched more than 7 days ago
WHERE fetched_at > DATEADD('day', -7, CURRENT_TIMESTAMP)
),
ranked_fetches_by_recency AS (
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY email
ORDER BY fetched_at DESC
) AS rank
FROM fresh_fetches
),
most_recent_fetches_by_email AS (
SELECT
fetched_at,
email,
clearbit_data
FROM ranked_fetches_by_recency
WHERE rank = 1
)
SELECT * FROM most_recent_fetches_by_emailusers_enriched – a view joining users and user_clearbit_data into combined, enriched records.
-- users_enriched
SELECT
u.*,
clearbit_data:person.employment.title AS title,
clearbit_data:company.name AS company_name,
clearbit_data:company.domain AS company_domain
FROM u
LEFT JOIN {{ ref('user_clearbit_data') || c ON u.email = c.emailusers_to_enrich – a view to compute the email values in users that aren't represented in user_clearbit_data. (We will need this to update the enrichment data)
-- users_to_enrich
SELECT u.email
FROM {{ source('enrichment', 'users') }} u
LEFT JOIN {{ source('enrichment', 'user_clearbit_data') }} c ON u.email = c.email
WHERE c.email IS NULLWith these model definitions in place, we can execute dbt run --models +users_enriched to build the tables and views, then SELECT * FROM users_enriched to view the results.
Deploying this in production
The ability to incorporate API data results into the declarative ELT flows enabled by SQL/dbt is a game-changer, and provides a worthy replacement for external workers that periodically run enrichment jobs against the data warehouse. However, it may be complex for some teams to set up and maintain these patterns, so it’s worth checking comfort levels with the stack components before taking the plunge. Here at Census, we are exploring ways to make this process more turnkey for our customers, so watch this space for updates.
- One pitfall that dbt users may recognize in the topology above is that the diff step introduces a cycle in the model graph, which isn't allowed in dbt since its dependency graph is a DAG. To avoid introducing a true dependency cycle, we use a source reference (rather than a ref) to
user_clearbit_datain theusers_to_enrichmodel, effectively changing dbt's instructions from "compute this dependency" to "use the contents of this table/view as-is". This is definitely something of a hack and has some downsides (like needing to be defined separately but kept in sync with theuser_clearbit_datamodel), but it enables us to do something here that we couldn't do otherwise.




